El otro día un cliente me decía que al guardar en el editor de bloques una entrada, le daba error en el servidor. Mirando bien el por qué del problema en la pestaña «Red» del navegador vi algo así como que había un error guardando el dato en la base de datos. También te aparece un mensaje así:

Mirando los datos que se enviaban me llamó la atención que en esa entrada el cliente, para mejorar la legibilidad del texto y hacerlo más simpático, había usado emoticonos. Y es que hace años los emoticonos se hacían directamente con diferentes caracteres estilo 🙂 pero ahora directamente podemos poner algo visual y es mucho mejor.
El caso es que ya en una entrada anterior hablamos de este mismo problema: al usar emojis no se podía guadar en la base de datos en WordPress y aunque dábamos una solución me he encontrado con algún cliente que ese método no le era suficiente.
¿Por qué? Porque el charset, el juego de caracteres, que usaba en esa tabla en la base de datos no era el correcto. Antiguamente, se usaba muchjo latin1 por defecto, que es una codifición que funciona bien con los caracteres que usamos en lenguas como el español o el inglés pero que no era compatible con caracteres propios del árabe, hebreo, etc.
Para resolver ese problema, se empezó a usar utf8, pero el tiempo pasó y en MySQL/MariaDB había caracteres, sobre todo caracteres modernos derivados de emojis y otras cosas que no son realmente letras como tal, que no estaban soportados. UTF8 solo puede manejar 3 bytes por carácter en MySQL/MariaDB y UTF8MB4 puede usar hasta 4 así que echad una cuenta simple:
- 3 bytes son 3 * 8 = 24 bits lo que significa 2²⁴ = 16.777.216 posiblidades diferentes pero claro
- 4 bytes son 4 * 8 = 32 bits que son 2³² = 4.294.967.296 esto ya es una verdadera pasada, hay sitio «para todos»
Así que nada, por lo general en WordPress en una instalación moderna en un alojamiento con una versión de sistema gestor de base de datos moderna lo tendrás por defecto, pero si no es caso, os enseño a cambiar vuestras tablas de latin1 o utf8 a utfmb4.
Cómo sé cuál juego de caracteres usan mis tablas
Pues muy fácil en phpMyAdmin lo tienes, mira en el listado de tablas:
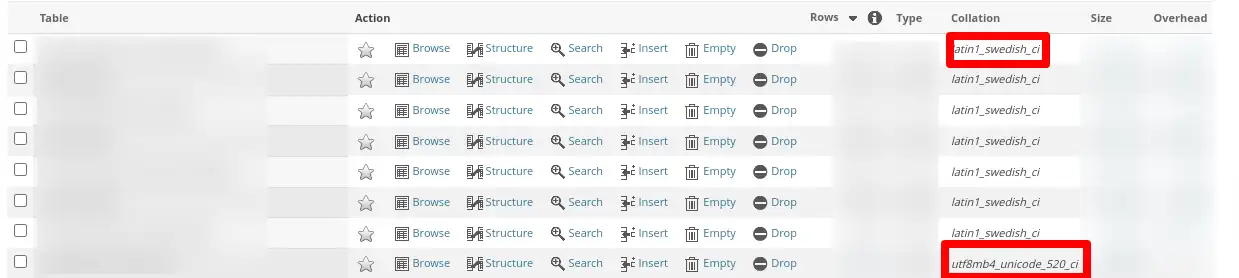
Si os fijáis, ahí no aparece el juego de caracteres como tal, sino el collation o colación que es la forma en que se ordenan los datos y que está íntimamente relacionado con el charset porque coincide la primera parte:
- latin1 seguido de algo será para latin1 como es lógico
- e igual para utf8mb4 seguido de algo que será para utf8mb4
De ahí podemos deducir el juego de caracteres.
Convertir tablas de latin1 o utf8 a utf8mb4
Lo primero es cambiar la base de datos para que por defecto se creen las tablas en este formato, podéis ejecutar en el SQL de phpMyAdmin algo así:
ALTER DATABASE mi_base_de_datos CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_520_ci;
Cambia la parte que corresponda con vosotros la de mi_base_de_datos.
Luego para cada tabla que no esté en el charset que queremos ejecutamos:
ALTER TABLE nombre_tabla CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
Con esto sería suficiente pero si queréis quedaros más tranquilos, podéis decirle a WordPress cuáles van a ser el juego de caracteres y colación por defecto, incluyendo en el wp-config.php las siguientes directivas en caso de que no existan ya:
define('DB_CHARSET', 'utf8mb4');
define('DB_COLLATE', 'utf8mb4_unicode_ci');
Y bueno, en cualquier web que tengáis de un cliente que use idiomas con lenguas con caracteres que son los latinos, seguro que ya están estos cambios aplicados porque normalmente, sin esto, no pueden funcionar.
 (Ninguna valoración todavía)
(Ninguna valoración todavía)
Julian
No controlo mucho, pero veo que pones a veces COLLATE = utf8mb4_unicode_520_ci y otras COLLATE = utf8mb4_unicode_ci
¿algun motivo? ¿es correcto o mejor siempre lo mismo? Gracias
Francisco Javier Carazo Gil
La collation es la forma que tiene la BBDD de por ejemplo saber cómo ordenar los datos, por eso tiene que ver con el charset porque en cada juego de caracteres hay datos que pueden diferir.
Para nuestro caso, en español/castellano, te dará igual usar una u otra a priori.
Aquí tienes el detalle:
utf8_unicode_ci (with no version named) is based on UCA 4.0.0 weight keys >(http://www.unicode.org/Public/UCA/4.0.0/allkeys-4.0.0.txt).
utf8_unicode_520_ci is based on UCA 5.2.0 weight keys (http://www.unicode.org/Public/UCA/5.2.0/allkeys.txt).